 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoulX-Transcriber: A Robust End-to-End Framework for Multi-Speaker Speech Transcription
Jun 01, 2026Recent advances in Automatic Speech Recognition (ASR) and Large Language Models (LLMs) have significantly improved speech understanding capabilities. However, multi-speaker speech transcription remains challenging task, constrained by highly similar speaker voices, rapid turn-taking transitions, overlapping utterances and inaccurate speaker boundary segmentation. These challenges become particularly pronounced in real-world conversational audio, where speaker dynamics and acoustic conditions are highly variable. This technical report presents SoulX-Transcriber, a unified multi-speaker transcription system that jointly models speaker diarization (SD) and ASR within an LLM-based framework. SoulX-Transcriber adopts a two-stage training strategy to improve both speaker discrimination and transcription robustness. In the first stage, speaker-aware multi-task continuous pre-training enhances speaker representation learning and boundary perception. In the second stage, supervised fine-tuning further optimizes the model for accurate end-to-end speaker-attributed transcription under complex multi-speaker conditions. SoulX-Transcriber delivers strong performance and robustness across multiple public benchmarks, including AliMeeting, AISHELL-4, and AMI, while maintaining high adaptability to multi-domain scenarios.
SoulX-Duplug: Plug-and-Play Streaming State Prediction Module for Realtime Full-Duplex Speech Conversation
Mar 16, 2026Recent advances in spoken dialogue systems have brought increased attention to human-like full-duplex voice interactions. However, our comprehensive review of this field reveals several challenges, including the difficulty in obtaining training data, catastrophic forgetting, and limited scalability. In this work, we propose SoulX-Duplug, a plug-and-play streaming state prediction module for full-duplex spoken dialogue systems. By jointly performing streaming ASR, SoulX-Duplug explicitly leverages textual information to identify user intent, effectively serving as a semantic VAD. To promote fair evaluation, we introduce SoulX-Duplug-Eval, extending widely used benchmarks with improved bilingual coverage. Experimental results show that SoulX-Duplug enables low-latency streaming dialogue state control, and the system built upon it outperforms existing full-duplex models in overall turn management and latency performance. We have open-sourced SoulX-Duplug and SoulX-Duplug-Eval.
SoulX-Singer: Towards High-Quality Zero-Shot Singing Voice Synthesis
Feb 08, 2026While recent years have witnessed rapid progress in speech synthesis, open-source singing voice synthesis (SVS) systems still face significant barriers to industrial deployment, particularly in terms of robustness and zero-shot generalization. In this report, we introduce SoulX-Singer, a high-quality open-source SVS system designed with practical deployment considerations in mind. SoulX-Singer supports controllable singing generation conditioned on either symbolic musical scores (MIDI) or melodic representations, enabling flexible and expressive control in real-world production workflows. Trained on more than 42,000 hours of vocal data, the system supports Mandarin Chinese, English, and Cantonese and consistently achieves state-of-the-art synthesis quality across languages under diverse musical conditions. Furthermore, to enable reliable evaluation of zero-shot SVS performance in practical scenarios, we construct SoulX-Singer-Eval, a dedicated benchmark with strict training-test disentanglement, facilitating systematic assessment in zero-shot settings.
Singer Identification Using Deep Timbre Feature Learning with KNN-Net
Feb 20, 2021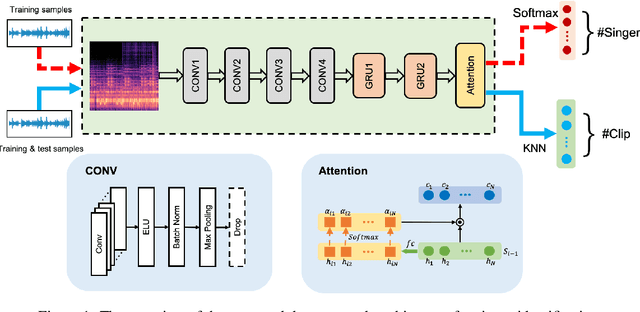
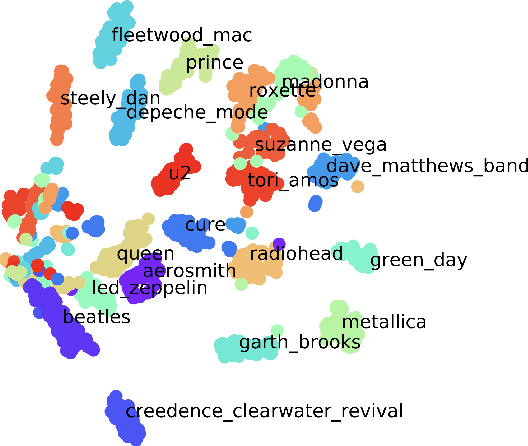
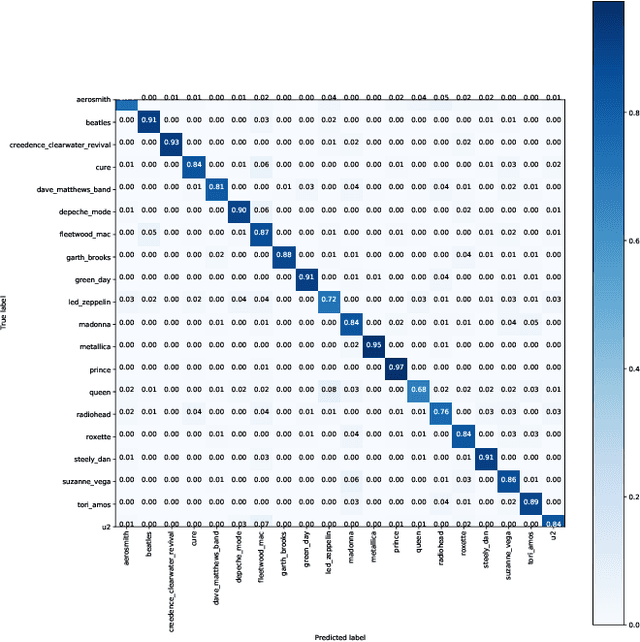
In this paper, we study the issue of automatic singer identification (SID) in popular music recordings, which aims to recognize who sang a given piece of song. The main challenge for this investigation lies in the fact that a singer's singing voice changes and intertwines with the signal of background accompaniment in time domain. To handle this challenge, we propose the KNN-Net for SID, which is a deep neural network model with the goal of learning local timbre feature representation from the mixture of singer voice and background music. Unlike other deep neural networks using the softmax layer as the output layer, we instead utilize the KNN as a more interpretable layer to output target singer labels. Moreover, attention mechanism is first introduced to highlight crucial timbre features for SID. Experiments on the existing artist20 dataset show that the proposed approach outperforms the state-of-the-art method by 4%. We also create singer32 and singer60 datasets consisting of Chinese pop music to evaluate the reliability of the proposed method. The more extensive experiments additionally indicate that our proposed model achieves a significant performance improvement compared to the state-of-the-art methods.